February 14, 2016 / Dennis Holinka
Topic 3 – Information Architecture layer
This week's posts go over the Information Architecture layer, the various perspectives, and related reflections in the blog.
Post 3 - Data Stewardship, Data Governance, and Big Data Modeling
Data stewardship is the role that people throughout the enterprise are tasked with in recognition that Data is an Asset and/or Data is a Liability and should be managed accordingly. The stewardship role expects that since data is important and its lifecycle maintenance should be properly managed then it follows that the quality and entry of the data and that a person should be put to take care of or steward the data in the particular enterprise domain. The role of data steward is shared between the business people who utilize the data in their respective daily contexts and the IT people who do the daily care and feeding of the systems and their systems of record where such data is placed under their charge for operations and maintenance during runtime and its persistence. Since data interactions spans beyond individuals into groups or across groups, precsise means of collaborating become essential and requires coordination. The coordination requires data governance with coordination based RACI roles defined to know who does what when why and where regarding data and is responsible for activities surrounding it beyond general stewardship.
Next enters Big Data with its promises of being able to extract knowledge and perhaps wisdom based insight from all the structured and unstructured data and content information across the enterprise as well as external information streams and stores. The big data emergence makes the role of data stewardship and activiites of data governance that much more expansive. The work of data stewardship and governance is already a large effort. Now with big data added, and the undetermined and uncertain sources of information make these roles close to almost impossible. Since all of this data needs to designed to work and related to many if not all of the other data within the Data Lake of big data, it will require specific types of modeling to prevent the Big Data - Data Lake from turning into a Data Cesspool. This requires the work and effort of Information Architects to use their Enterprise Architecture skills and understanding of an extended enterprise and apply it to the extended information architecture boundaries that span enterprises into its overarching ecosystem and into various enterprise integration knowledge domain relatioships.

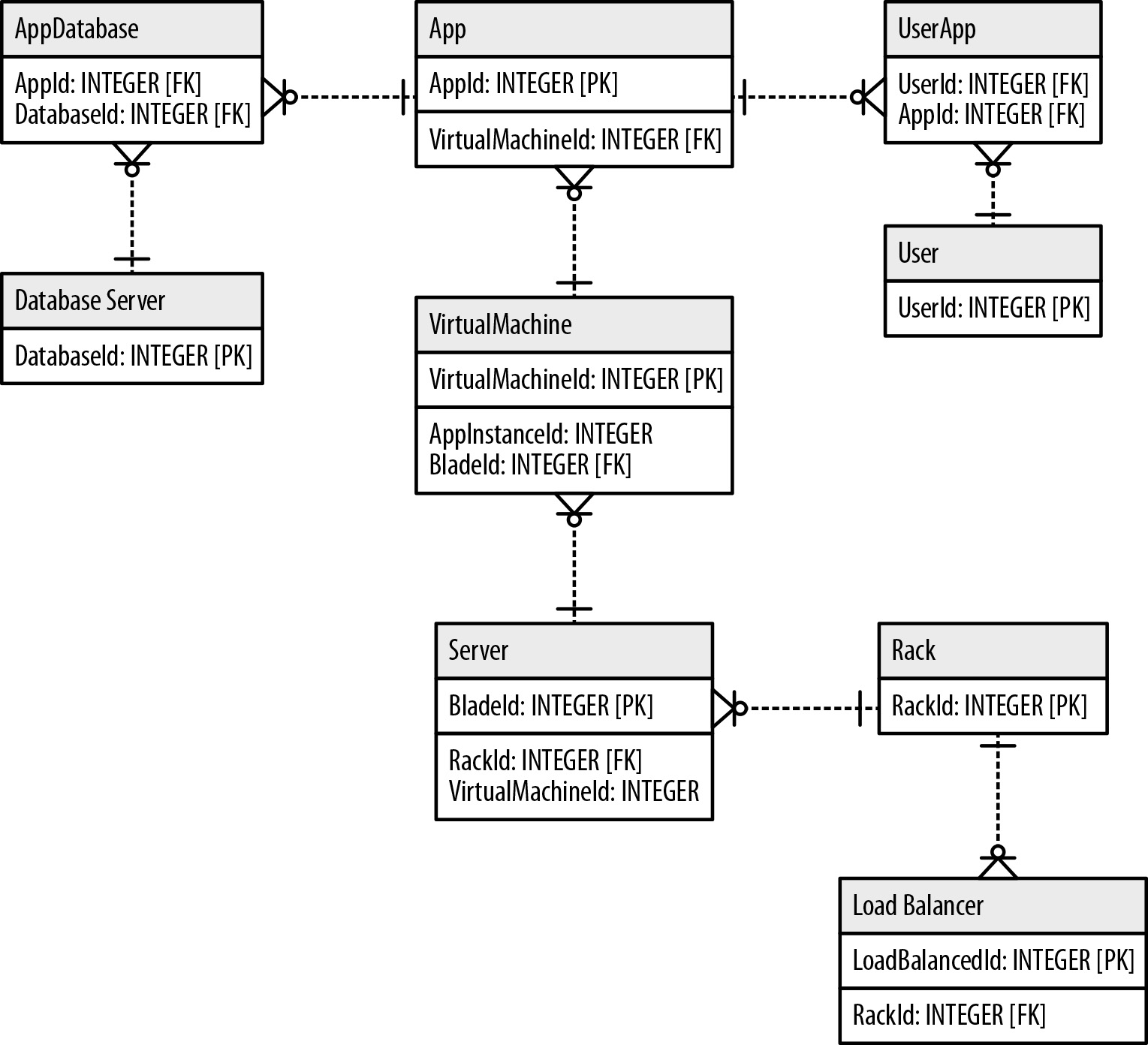
Figure: Traditional Relational Database Model that forces graphical concepts into it paradigm
{kind=link}
If things weren't hard already, next enters the modeling of new Big Data unstructured models of NoSQL data model of key values that are distributed but related to other key value pair table like structures that are partitioned across multiple servers with non consistent (e.g. ACID) HA redundant data stores. In addition, Big Data has been using graph databases that are used to store and analyze graph based data instead of trying to shoe-horn graphical and/or NoSQL data into relational data stores in the form of traditional ERDs. The new modeling approaches of which I have shown one example are more robust and can more easily depict the natural relatioships that are attempted to being solved. From concept to stewardship to governance and abstract knowledge depictions of what is being modeled to be governed lead us to the conclusion that the work of the Information Architect is becoming more complex and requires extensive modeling skills to take on the new emerging areas beyond the tradional role and relational structure allowed for in the past.
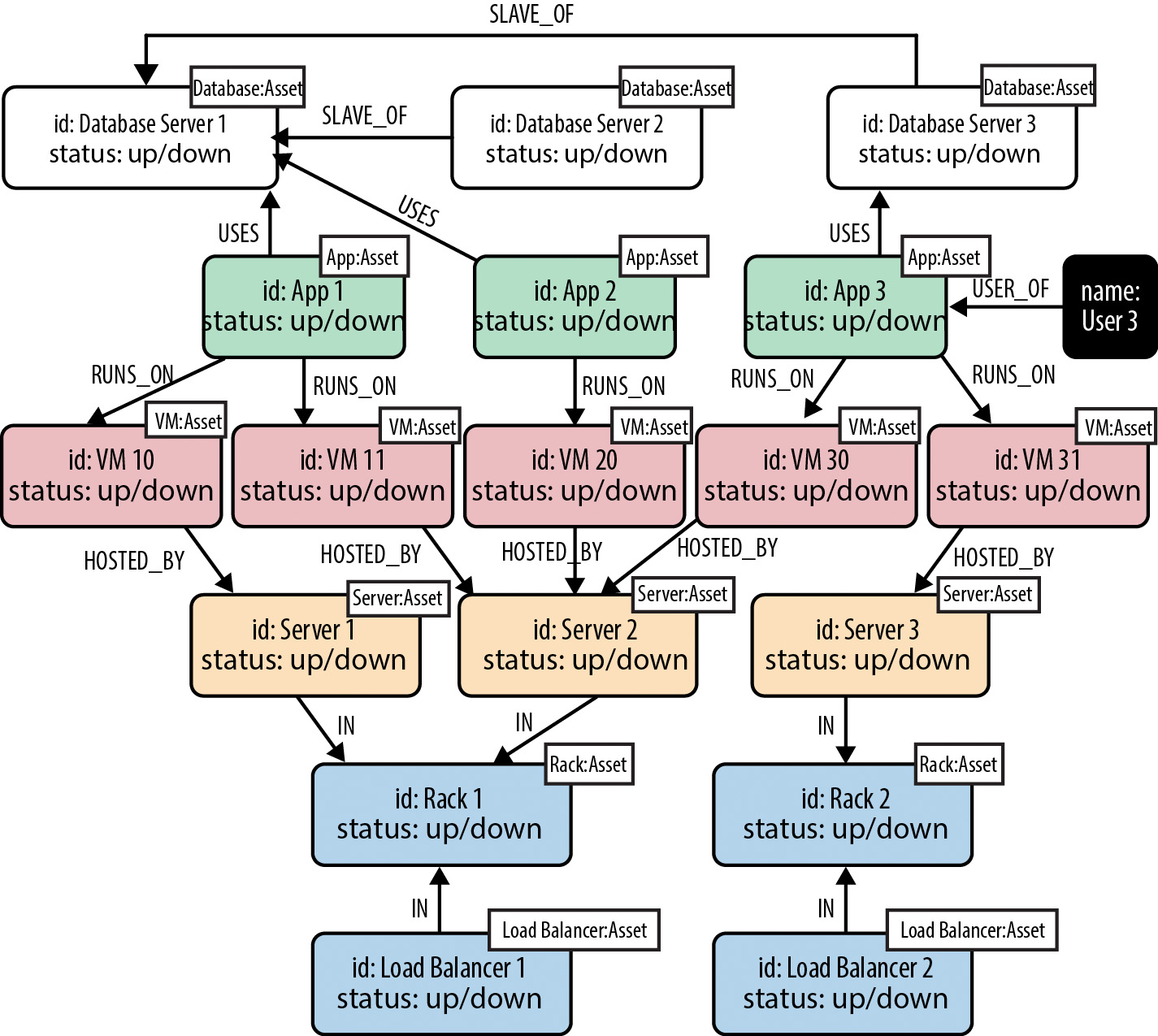
Figure: Graphiical Database Model that is more akin to the domain relations being developed
{kind=link}
It was really a nice article and i was really impressed by reading thiS Big data hadoop online Course Bangalore
ReplyDelete